Alphabet Soup: What Does Artificial Intelligence Really Mean?

This summer, CFA Institute and the Asset Management Association of China invited me to host the Fintech Investment Forum in Hangzhou, China. The standout speaker on artificial intelligence (AI) was Dr Noah Silverman, founder of Helios.ai, a consulting firm in Hong Kong. His presentation focused on cutting through the hype surrounding AI and provided an enlightening summary of the issues to consider when following this space.
Currently, it is popular for public figures to bravely predict and lament the impending end of white-collar jobs “imminently” at the hands of AI. Given the demonstrable inability of public intellectuals to predict events over recent years, we should take these proclamations as something less than Sermons on the Mount. The premise of Dr. Silverman’s presentation was that this current AI/machine learning/ deep-learning moment has arisen partly because of the media’s tendency to overuse click-bait headlines. A favourite recent example of mine describes a car electric seat memory function, available since at least the 1980s, as ‘artificial intelligence’:
“The E-Pace inherits Jaguar’s Smart Settings artificially intelligent machine learning system from the I-Pace that can store up to 10 driver profiles. The car detects the driver by their key fob and mobile phone Bluetooth signal, and adjusts accordingly. “
This sensationalism is necessary in the face of advertising revenue concentrating on winner-take-all platforms.
This phenomenon has also affected financial services organisations that want to be viewed as “with it” and as embracing fintech (a concept we previously described as being so vague and all-encompassing as to be totally useless) to stave off charges of complacency. In turn, the tech space is happy to oblige with off-the-shelf AI and machine learning tools, such as TensorFlow, to create start-up companies that are promising to enable AI to disrupt every possible niche. Although we can rely on the price discovery mechanism to eventually chew through many of these start-ups and determine which ones are useful and which ones are not, we also can get a head start on this process by predicting likely prospects for this technology.
As Dr Silverman noted in his presentation, the particular issue with the current wave of AI, and the most popular technique for enabling AI – machine learning — is that it is in some ways mostly a branding exercise. Increasingly there is evidence that modern machine learning is still far closer to the Solver function in Microsoft Excel than it is to Space Odyssey’s HAL 9000.
In this blog, and the following blog, we navigate the jargon of AI and then throw some cold water on the AI hype machine. We will see that machine learning is a useful and powerful tool, but it is no more than that.
I can’t do that, Dave
Defining AI is an impossible task that has stirred much debate over the decades. That said, there is a consensus that we can distinguish between artificial intelligence within a specific domain (i.e. a computer performing a given task, but no other task, in a way that mimics what an intelligent being would do) and a general artificial intelligence that can act across different domains (i.e. HAL 9000).
There are many ways to create task-specific AI (perhaps more truthfully described as automation). For example, one could attempt to code all possible decision trees and behaviours in an endless stream of if–then statements (i.e., to a large extent, what driverless cars rely on to this day). For now, we will ignore how to create general AI because nobody really knows.
In addition to hard-coding behaviour as just described, another approach to creating AI, in the automation sense, is machine learning. Most machine learning techniques are useful for automation, while not being in any way intelligent in the general AI sense. At its core, machine learning is simply an optimisation algorithm that enables a computer to iteratively estimate increasingly accurate associations between input data and output data, given a sample of training data.
Some examples of these associations for certain applications follow:
- Statistical analysis – association between input data of an independent variable and output data of a predicted dependent variable.
- Image recognition – association between input images of animals and output labels, such as “cat,” “dog,” and so on.
- Customer profiling – association between input data on customers and output labels, such as “creditworthy,” “credit risk,” and so on.
- Driverless cars – association between visual and radar input data and output data on rates and directions of steering wheel adjustments.
Backpropagating to the future
The fundamental concept behind all machine learning technology is some manifestation of backpropagation — a technique that can be summarised as follows:
- An initial attempt is made to approximate the desired output.
- The error between the estimate and the desired output is calculated.
- The size and direction of this error is used to adjust the various parameters used to make the estimate in the first place (i.e., backpropagation) to make the next estimate have a smaller error.
- The process is repeated until the errors are sufficiently small.
This process should sound familiar to anyone with a passing familiarity of statistics because it is the foundation of linear regression, which seeks to minimise the total sum of all the errors between the sample data points and the estimated linear trendline (with the errors squared so that errors with different directions don’t cancel out). It just so happens that linear regression has an analytical solution that obviates the need to perform this process iteratively, but the more powerful generalized method of moments approach is essentially a type of machine learning from the 1980s (in fact, most machine-learning techniques are from this period).
What I have just described often is referred to as classical machine learning, which may be more accurately described as algorithmic optimisation. We can categorize these techniques into two groups, both of which may sound familiar:
- Supervised learning: This process denotes machine-learning techniques in which the desired outputs that the algorithm is trying to reproduce are known and labelled, making the process of error calculation and correction easier. Supervised learning is deployed for classification or regression problems. In this technique, the backpropagation mechanism simply ensures that the input data “fits” the output labels as closely as possible — a nonparametric (in the sense of not assuming an underlying probability distribution), hyper-dimensional regression or optimization problem. For example, an image recognition algorithm performs supervised learning if the training set of animal pictures is labelled “cat” and “dog” so that the algorithm knows with certainty when it has guessed correctly and when it has made an error.
- Unsupervised learning: This process denotes machine-learning techniques in which the input data are not labelled, and the desired outputs are not known. In this technique, the goal of the algorithm is to discover groups (or clusters) within data that are nonintuitive or unobservable to the human eye, according to some metric that is learned by the algorithm. For example, dimensionality reduction is a technique that seeks to reduce the number of dimensions of the data by finding a subset of data characteristics that satisfactorily explains the most salient features. For statistically minded readers, these techniques are similar to principal components analysis.
Supervised and unsupervised learning optimize a “fit” or a solution to a given problem, in the usual statistical sense. They do not claim to attain some kind of intuition about an abstract concept, like “catness.” They are, essentially, a direct extension of statistics and would be better described as algorithmic learning, given that they have as much in common with AI as a torque wrench that “knows” when to stop applying force.
The result in classical machine learning is a mapping structure between vectors of input data and vectors of output data (i.e., a vector space). The geometric distance between vectors gives the algorithm a way to measure relationships among different bits of data. This technology is the basis of translation tools and sentiment analysis.
This is how natural language processing “knows” that Paris is to France as Rome is to Italy — because Paris will lie on the same vector as Rome, Italy, and France will lie on another. Thus, the distance between Paris and France will be the same as the distance between Italy and Rome. One can find more humorous examples of wordspace algebra, as it is called, such as “President − Power = Prime Minister.”
Other methods, such as reinforcement learning or semi supervised learning, also exist, but they are not as widely used. However, most of the well-known and dramatic breakthroughs in machine learning are a result of deep-learning algorithms.
Shallow dive into deep learning
Deep learning is a shorthand term for machine learning using multilayer (deep) neural networks. It is more complicated and potentially more interesting than the pure-optimization techniques of supervised and unsupervised learning described earlier. It is also responsible for most of the exciting breakthroughs that have been reported in the media.
As opposed to classical machine learning, which does not have any ambitions for creating general AI, neural networks (particularly the “deep” ones) more explicitly try to replicate biological intelligence by mimicking the brain structure of intelligent beings.
Confusingly, neural networks also can be used to improve the performance of machine-learning techniques that seek only to automate, thus giving those techniques the veneer of intelligence (hence, the current wave of AI hype). Deep learning is, in this way, a poorly defined term because it represents both a new tool for conducting supervised and unsupervised learning but is also a unique approach that justifies its own place in the machine-learning taxonomy.
Deep learning relies on neural networks, so much so that you could argue that deep learning is simply the application of neural networks to machine-learning problems (see diagram). Technically, the “deep” part of the learning refers to neural network techniques in which the “learning” from data occurs over multiple or “deep” layers — that is, the data are processed by different layers of the algorithm before returning some output. There are also simpler or “shallow” neural networks that are useful for other tasks or as components of larger systems.
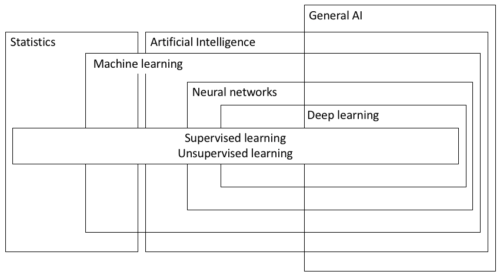
Essentially, classical machine-learning techniques, like supervised and unsupervised learning, are optimization algorithms that have the dubious claim of being considered a type of AI, whereas neural networks place an explicit emphasis on mimicking the neural structure of the brain with data inputs being processed by “perceptrons.”
Perceptrons (i.e., artificial neurons) are mathematical functions that perform the following simple tasks:
- Receive data inputs;
- Scale data inputs according to a predefined scaling function (to avoid “blowing up” the “neuron” with an outsized input); and
- Activate or not — that is, “decide” whether or not the signal is important enough to send to the next layer — according to some predefined hurdle.
These perceptrons are connected in a network that enables signals to be passed between layers of perceptrons, and in which the strength of the connection is the main parameter being optimized by the backpropagation algorithm.
To the extent that any of the techniques discussed in this blog will result in more than the equivalent of a parrot learning to “talk,” deep learning is currently the only hope for the future.
Cliffhanger
This discussion of the taxonomy of AI should be interesting for CFA Institute members because most financial analyst applications of machine learning are derived from the classical machine learning group of techniques. For example, analysis of asset prices is mostly based on techniques such as logistic regression, principal component analysis, and so on.
Deep learning, in contrast, is useful mainly for processing unstructured, and particularly visual, big data, such as sensor data from drones and satellites. For example, this sort of data can be useful to obtain predictive signals of footfall in supermarkets or miles travelled by trucks as leading indicators of economic activity. These data, however, will simply be consumed by financial analysts and not created by them.
It is likely therefore that deep learning will be useful for generating new signals from sensor data, but it is unlikely that it will help to create pitch books in PowerPoint. Predictions of the wholesale destruction of white-collar jobs are premature.
Finally, there is increasing evidence that rather than being the beginning of something transformative, deep learning is, in fact, the end of a process that began 30 years ago, something that will be discussed in the next blog.
Image Credit: ©Fintech